Lecture6 Raft(1)
讲义:http://nil.csail.mit.edu/6.824/2020/notes/l-raft.txt
视频:https://www.bilibili.com/video/BV1R7411t71W?p=6
参考笔记:https://mit-public-courses-cn-translatio.gitbook.io/mit6-824/lecture-06-raft1
对应raft论文前五章
脑裂(Split-Brain)
之前学习的系统
- MapReduce 依靠单一的master来复制计算
- GFS master来决定数据备份
- VM-FT,primary&backup,出现故障时以来单机的test-and-set服务
它们存在一个共性:它们需要一个单节点来决定,在多个副本中,谁是主(Primary)。
- 好处:单节点不可能否认自己,它的决策就是整体的决策。
- 缺点:可能出现单点故障(Single Point of Failure)。
使用单点更重要原因是,可以有效避免脑裂(Split-Brain)
脑裂会导致一些问题,比如在以下的网络拓扑中,s1、s2是两个test-and-set服务,我们要求能够容错
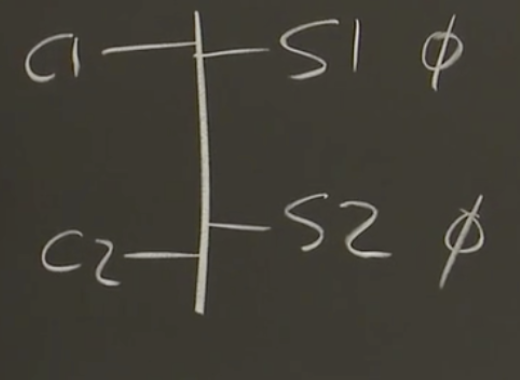
假设网络出现故障,c1只能和s1通信,c2只能和s2通信
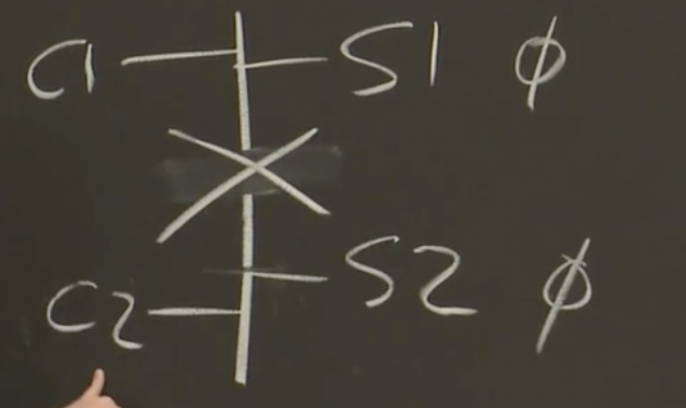
要么等待两个服务器响应,那么这个时候就没有容错能力;
要么只等待一个服务器响应,那么就会进入错误的场景(c1、c2都能拿到锁),而这种错误的场景,通常被称为脑裂。
这是上世纪80年代之前要面临的挑战。当时有多副本系统的要求。例如,控制电话交换机的计算机系统,或者是运行银行系统的计算机系统。当时的人们在构建多副本系统时,需要排除脑裂的可能。这里有两种技术:
- 第一种是构建一个不可能出现故障的网络。当网络不出现故障时,那就意味着,如果客户端不能与一个服务器交互,那么这个服务器肯定是关机了。
- 另一种就是人工解决问题。默认情况下,客户端总是要等待两个服务器响应,如果只有一个服务器响应,永远不要执行任何操作。相应的,给运维人员打电话,让运维人员去机房检查两个服务器。要么将一台服务器直接关机,要么确认一下其中一台服务器真的关机了,而另一个台还在工作。所以本质上,这里把人作为了一个决策器。而如果把人看成一台电脑的话,那么这个人他也是个单点。
这些方案都有缺陷,因为人工响应不能很及时,而不出现故障的网络又很贵,但是这些方法至少是可行的
过半投票(Majority Vote)
如果想要自动解决脑裂问题,一个关键思路就是过半投票。
要求:服务器的数量要是奇数,而不是偶数。6.1的例子中,中间出现故障,那两边就太过对称,它们看起来完全是一样的,它们运行了同样的软件,所以它们也会做相同的事情,这样不太好(会导致脑裂)。
思路:如果系统有 2 * F + 1 个服务器,那么系统最多可以接受F个服务器出现故障,仍然可以正常工作。
过半指的是所有服务器数量的一半,而不是当前开机服务器数量的一半
这样的系统通常被称为多数投票(quorum)系统。
Raft
详见raft论文阅读与lab实现~
Log
Log的作用:
- 用来对操作排序的一种手段
- Followe收到了操作,但是还没有执行操作时,需要将这个操作存放在某处,直到收到了Leader发送的新的commit号才执行
- Leader需要在它的Log中记录操作,因为这些操作可能需要重传给Follower
- 帮助重启的服务器恢复状态
Leader
为什么需要leader?
通常情况下,如果服务器不出现故障,有一个Leader的存在,会使得整个系统更加高效。因为有了一个大家都知道的指定的Leader,对于一个请求,你可以只通过一轮消息就获得过半服务器的认可。对于一个无Leader的系统,通常需要一轮消息来确认一个临时的Leader,之后第二轮消息才能确认请求。
每个term至多有一个leader