Lecture4 Primary-Backup Replication
讲义:http://nil.csail.mit.edu/6.824/2020/notes/l-vm-ft.txt
视频:https://www.bilibili.com/video/BV1qk4y197bB?p=4
参考笔记:https://mit-public-courses-cn-translatio.gitbook.io/mit6-824/lecture-04-vmware-ft
论文阅读
参考:
https://tanxinyu.work/vm-ft-thesis/
https://www.cnblogs.com/brianleelxt/p/13245754.html
一篇不错的解读:
Abstract
基于通过另一台服务器上的备份虚拟机复制主虚拟机(VM)执行的方法实现了一个容错虚拟机(FT-VM),通常会将实际应用程序的性能降低不到10%。
- 介绍 basic idea
- 讨论替代选择和实现细节
- 基准测试和实际应用的性能结果
1 Introduction
实现ft的常见方法是主从备份**(primary/backup approach)**,在主服务器故障时由从服务器接管服务。
- 备份服务器与主服务器保持几乎相同
- 出错时可以立即切换,客户端无感知去,且不会有数据丢失
- 一种实现方法是将主服务器的修改实时发送给从服务器,但涉及到很多内存更改,需要很大的网络带宽
状态机方法**(state-machine approach)**可以使用更少的带宽
- 用确定性状态机对servers建模,通过从相同的初始状态启动服务器并确保他们以相同的顺序接受请求来保持同步
- 大多数服务器有不确定性操作,需要额外的coordination来确保主从同步
- 保持同步所需的额外信息量远少于主服务器中正在修改的状态量(主要是内存更新)
对于物理机而言,实现coordination很困难,但是运行在hypervisor上的虚拟机可以很好地实现状态机方法。
- hypervisor完全控制虚拟机的执行,包括所有输入的交付,因此hypervisor能够捕获主虚拟机上非确定性操作的所有必要信息,并在备份虚拟机上正确重播这些操作。
- 无需修改硬件
允许我们记录主备份执行情况并确保备份执行相同的基本技术称为确定性重播
论文组织
- 描述我们用于保证启动备份VM时候不丢失数据的设计和详细协议
- 描述一些为了构造一个鲁棒、完备、自动的系统需要考虑的实际问题
- 描述了一些设计选择,并讨论这些设计的tradeoff
- 给出实现的性能报告
- 最后,描述相关工作和结论
2 Basic FT Design
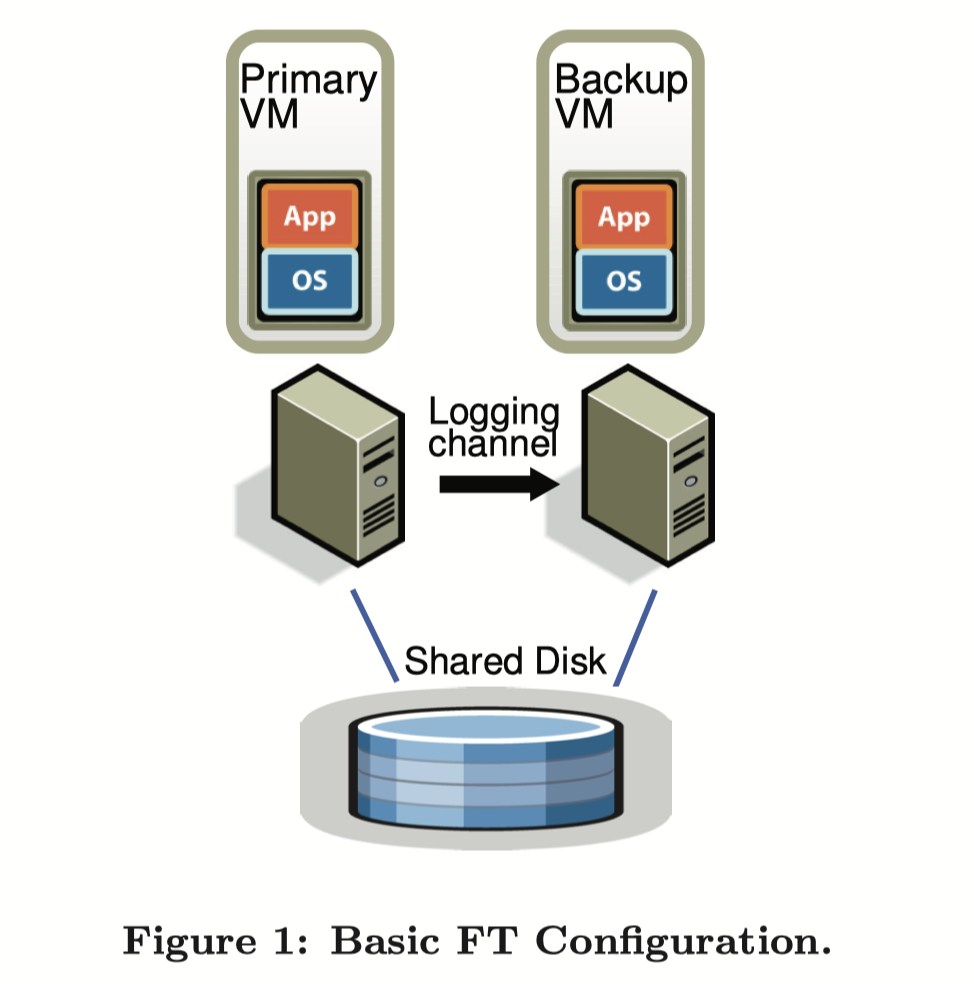
- 在不同的物理机上运行primary VM和backup VM,虚拟机的虚拟磁盘在共享存储上
- primary VM接收到的操作会通过logging channel转发给backup VM,对于非确定性的操作,还将发送额外的信息,确保备机以确定性的方式执行这些操作。
- Backup VM总是和primary VM执行一样的操作,但是只有primary的输出会被返回给客户。
- 系统使用 Primary VM 和 Backup VM 之间的心跳包和 Logging Channel 上的流量监控来检测 Primary VM 或 Backup VM 是否是失效 。此外,必须确保 Primary VM 和 Backup VM 中只有一个接管执行来避免脑裂。
2.1 确定性重播
原理:如果两个确定性状态机从相同的状态开始,执行相同的操作序列,那么会输出相同的结果。
三个挑战
- 正确捕获所有输入和必要的不确定性输入来保证备机确定性执行;
- 正确在备机执行不确定性输入;
- 不降低系统的性能;
确定性重放记录 primary 的输入和 primary 执行相关的所有可能的不确定性,记录在 log entry 流中,发送给 backup 并使其重放 :
- 对于不确定的操作,将记录足够的信息,确保其在 backup 上重新执行能够得到相同的状态和输出
- 对于不确定的事件,如定时器或 IO 完成中断,事件发生的确切指令会被记录下来,重放时,backup VM 会在指令流中相同的位置重放这些事件
2.2 FT Protocol
execution of the primary VM不是被记录到disk中,而是通过logging channel发送到backup VM,因此我们需要严格的FT protocol来保证实现容错。
课程
State transfer
传输的是可能是内存
- 把所有状态都传输,简单
- 但是占用网络资源大
Replicated State Machine
将来自客户端的操作或者其他外部事件,从Primary传输到Backup
- 传输内容很小
- 实现复杂
思想
VMware FT的独特之处在于,它从机器级别实现复制,因此它不关心你在机器上运行什么样的软件,它就是复制底层的寄存器和内存。你可以在VMware FT管理的机器上运行任何软件,只要你的软件可以运行在VMware FT支持的微处理器上。这里说的软件可以是任何软件。
- 缺点是,它没有那么的高效
- 优点是,你可以将任何现有的软件,甚至你不需要有这些软件的源代码,你也不需要理解这些软件是如何运行的,在某些限制条件下,你就可以将这些软件运行在VMware FT的这套复制方案上。VMware FT就是那个可以让任何软件都具备容错性的魔法棒。
非确定性事件
计算机中的一些指令不由计算机内存的内容而确定的行为
- 客户端输入
- 客户端请求何时送达,会有什么样的内容,并不取决于服务当前的状态,是不可预期的
- 输入也就是一个网络数据包,一部分是数据内容,一部分是中断
- 过程
- 输入-> 网卡的DMA(Direct Memory Access)会将网络数据包的内容拷贝到内存 -> 触发一个中断 -> 操作系统在处理指令的过程中消费这个中断
- 对于Primary和Backup来说,这里的步骤必须看起来是一样的,也就是说最好要在相同的时间,相同的位置触发中断,否则执行过程就是不一样的,进而会导致它们的状态产生偏差
- wired instruction
- 随机数生成器
- 获取当前时间的指令,在不同时间调用会得到不同的结果
- 获取计算机的唯一ID
- multicore
- 多核并发,例如两个核同时向同一份数据请求锁,在Primary上,核1得到了锁;在Backup上,由于细微的时间差别核2得到了锁
- 本论文没有讨论,针对的是单核系统
这需要通过 Log Channel 来进行交互,Robert教授猜测 Log 条目内容如下:
事件发生时的指令序号。因为如果要同步中断或者客户端输入数据,最好是Primary和Backup在相同的指令位置看到数据,所以我们需要知道指令序号。这里的指令号是自机器启动以来指令的相对序号,而不是指令在内存中的地址。比如说,我们正在执行第40亿零79条指令。所以日志条目需要有指令序号。对于中断和输入来说,指令序号就是指令或者中断在Primary中执行的位置。对于怪异的指令(Weird instructions),比如说获取当前的时间来说,这个序号就是获取时间这条指令执行的序号。这样,Backup虚机就知道在哪个指令位置让相应的事件发生。
日志条目的类型,可能是普通的网络数据输入,也可能是怪异指令。
最后是数据。如果是一个网络数据包,那么数据就是网络数据包的内容。如果是一个怪异指令,数据将会是这些怪异指令在Primary上执行的结果。这样Backup虚机就可以伪造指令,并提供与Primary相同的结果。
输出控制
客户端输入到达Primary。
Primary的VMM将输入的拷贝发送给Backup虚机的VMM。所以有关输入的Log条目在Primary虚机生成输出之前,就发往了Backup。之后,这条Log条目通过网络发往Backup,但是过程中有可能丢失。
Primary的VMM将输入发送给Primary虚机,Primary虚机生成了输出。现在Primary虚机的里的数据已经变成了11,生成的输出也包含了11。但是VMM不会无条件转发这个输出给客户端。
Primary的VMM会等到之前的Log条目都被Backup虚机确认收到了才将输出转发给客户端。所以,包含了客户端输入的Log条目,会从Primary的VMM送到Backup的VMM,Backup的VMM不用等到Backup虚机实际执行这个输入,就会发送一个表明收到了这条Log的ACK报文给Primary的VMM。当Primary的VMM收到了这个ACK,才会将Primary虚机生成的输出转发到网络中。
否则,可能出现primary挂掉,但log还没传到backup,从而导致主从不一致的情况
缺点:在某个时间点,Primary必须要停下来等待Backup,这对于性能是实打实的限制
Test-and-Set
在6.824这门课程中,有个核心的规则就是,你无法判断另一个计算机是否真的挂了,你所知道的就是,你无法从那台计算机收到网络报文,你无法判断是因为那台计算机挂了,还是因为网络出问题了导致的。
- Test-and-Set服务不运行在Primary和Backup的物理服务器上,我们可以认为运行在单台服务器。
- 当网络出现故障,并且两个副本都认为对方已经挂了时,Test-and-Set服务就是一个仲裁官,决定了两个副本中哪一个应该上线。