Lecture 1: Introduction
论文翻译https://blog.csdn.net/tantexian/article/details/62040046
论文https://pdos.csail.mit.edu/6.824/papers/mapreduce.pdf
视频https://www.bilibili.com/video/BV1R7411t71W?p=1
LAB1:http://nil.csail.mit.edu/6.824/2020/labs/lab-mr.html
MapReduce
Abstract
- programming model
- map: a key/value pair to generate a set of intermediate key/value pairs
- reduce: merges all intermediate values associated with the same intermediate key
- programs written in this functional style
- parallelized
- executed on a cluster
Introduction
往往使用于:
- straightforward
- input data is large
期望:
- a new abstraction
- express the simple computation
- hide the messy details of parallelization, fault-tolerance, data distribution and load balancing
大纲
- section2:编程模型、例子
- section3:实现
- section4:优化
- section5:性能测试
- section6:扩展
Programming Model
模型:
- Map:接收一个输入,输出一组KV,传递给reduce
- Reduce:接收一个K,一组V,对values进行merge。一般来说输出一个或零个结果,迭代处理。
例子:
wordcount

Implementation
Exection Overview
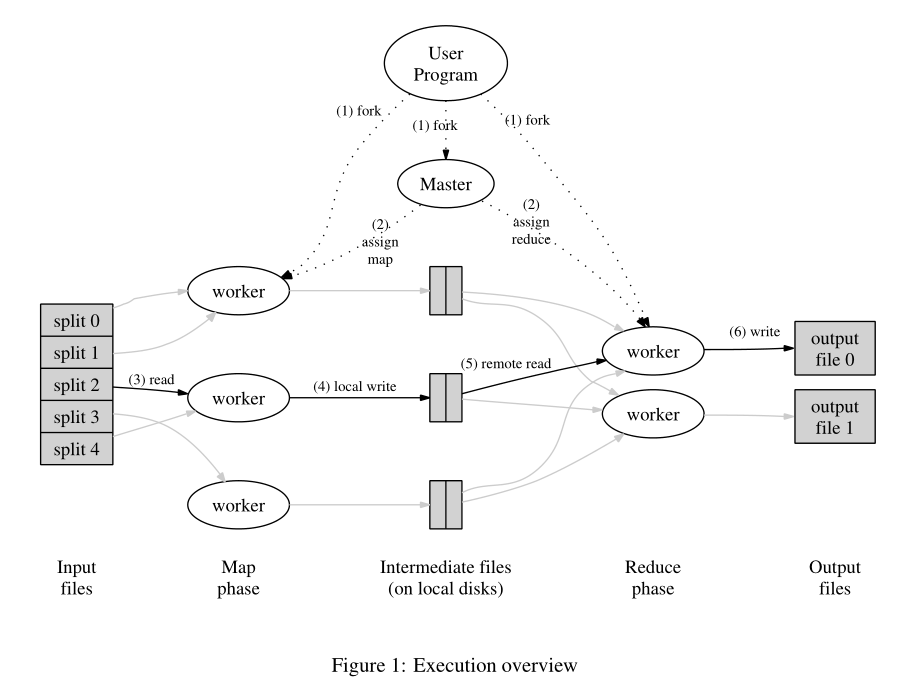
- 将输入文件分片,并在集群上起程序副本
- master程序负责分配,每个worker接收一个map task或者reduce task
- worker接收到map task,读取输入分片,根据用户定义的map function处理,将结果存储在buffer memory中
- 阶段性地将buffer中的中间结果写进磁盘,并根据partition function进行划分(比如 hash(key)modR) ,传递回给master
- master分配reduce task,通过RPC读取map worker disk中的的buffer data,并进行排序(因为可能多个kay被划分给同一个reduce worker);如果内存不够,进行外排序
- reduce worker遍历中间结果,根据reduce function进行处理,将结果append到该partition的输出文件中
- 所有map task和reduce task结束后,master通知用户处理完毕
Master Data Structure
For each map task and reduce task
- state
- idle
- in-progress
- completed
- identity of the worker machine
- for non-idle tasks
Fault Tolerant
Worker Failure
- master 阶段性地 ping 各个 worker 节点,失联标记为 failed
- 对于 failed 的 worker
- in-process的task标记为idle
- completed的task标记为idle
- completed 的 map task 需要重新执行,因为结果存储在local disk中
- completed 的 reduce task 不需要重新执行,因为结果存储在外部文件系统
- map task 如果先前在A上执行,后来在B上执行,相应的reducing task需要被告知,从B上那读中间数据
Master Failure
整个 MapReduce 集群中只会有一个 Master 结点,因此 Master 失效的情况并不多见。
Master 结点在运行时会周期性地将集群的当前状态作为保存点(Checkpoint)写入到磁盘中。Master 进程终止后,重新启动的 Master 进程即可利用存储在磁盘中的数据恢复到上一次保存点的状态。