Lab2 Raft
讲义:http://nil.csail.mit.edu/6.824/2020/labs/lab-raft.html
阅读材料:
- students-guide-to-raft
- advice about locking and structure for concurrency
- 如何才能更好的学习 MIT 6.824 ?
实现参考:https://mp.weixin.qq.com/s/djjfz2oGosoj7fChEe9AdQ
0 准备工作
0.1 论文与阅读材料
在动手写代码之前,一定要仔细阅读论文和阅读材料。在实现的过程中,遇到的很多问题都可以在论文和阅读材料中找到答案。
论文的图2为本实验的一个重要参考
⚠️实现的过程除了各个RPC下的implementation,右下角的Rules for Servers也需要考虑!

0.2 Debug
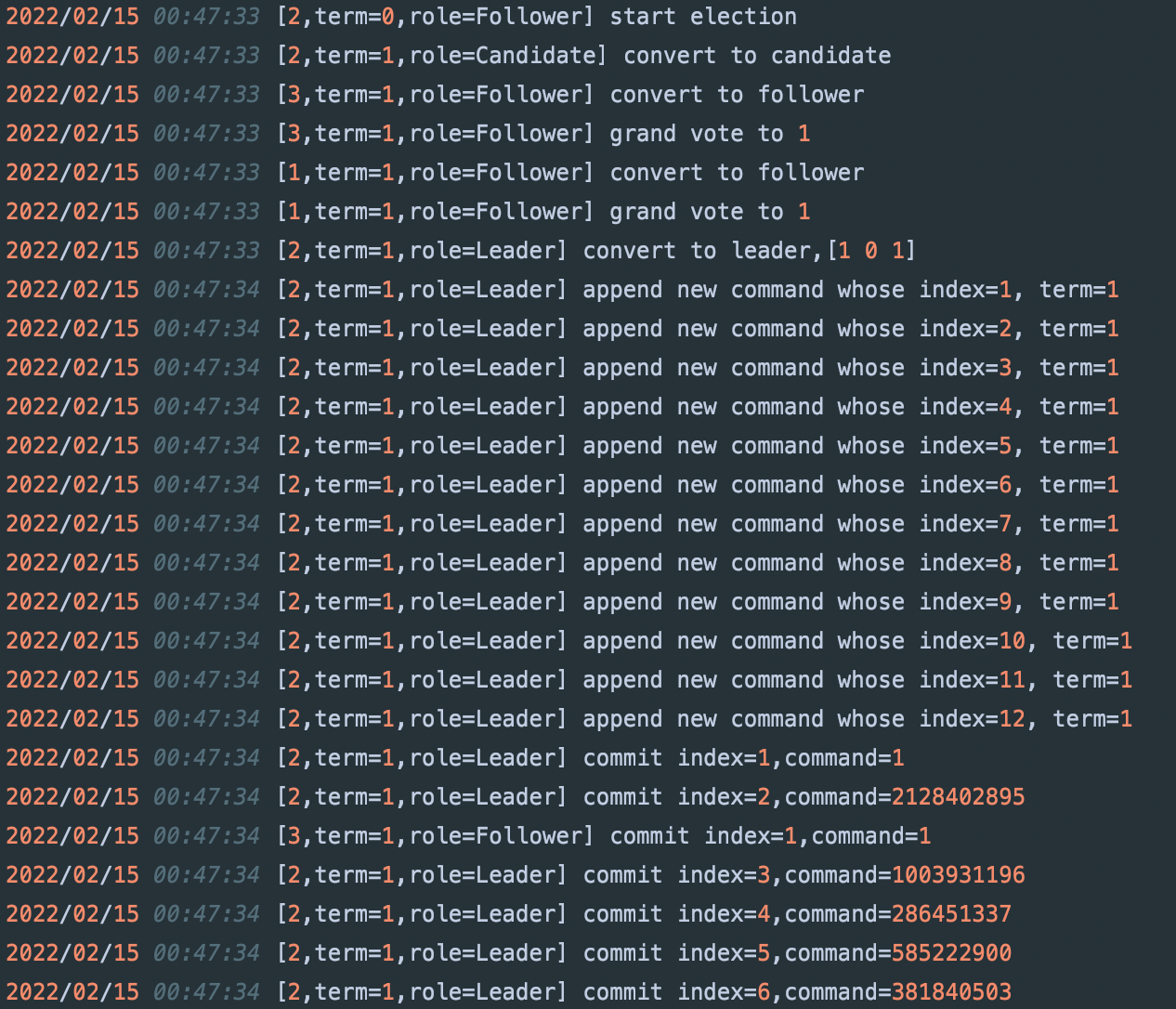
由于是分布式系统,可以在函数的关键位置打印日志来进行debug。
Lab为我们在util.go中提供了一个DPrintf工具,但个人建议对其再进行一层封装,可以打印Raft节点状态信息以及日志内容。
func (rf *Raft) printf(format string, a ...interface{}) {
s := fmt.Sprintf("[%d,term=%d,role=%v] %s", rf.me+1, rf.currentTerm, rf.role, format)
DPrintf(s, a...)
}
使用时,只需要将util.go中的Debug设为1,即可打印日志,如下:
0.3 测试脚本
由于是分布式系统,测试随机性较大,因此我写了一个简单的测试脚本,可用于循环多次测试,保证没有Bug遗漏。
#!/bin/sh
str2="PASS"
read -p "Enter loop times>" loop_time
read -p "Which part want to test?(A/B/C)>" part
i=0
success=true
while [ $i -lt $loop_time ]
do
let 'i++'
go test -run 2"$part" > test.log
result=$(tail -n 2 test.log | head -1)
if [[ $result =~ $str2 ]];then
echo "PASSED TEST TIMES:"$i
else
success=false
echo "FAIL AT" $i "TIMES"
break
fi
done
if ($success)
then
echo "PASS ALL TEST" $loop_time "TIMES"
fi
1 PartA-选举
PartA部分实现了选举,对应论文5.1~5.2
除了图2,图4也是partA实现的重要依据
1.1 测试分析
PartA有两个测试
TestInitialElection2A- 测试是否能够正常选举,并在保持网络没有波动的情况下term不会发生变化(换言之就是需要实现简单的心跳)
TestReElection2A- 测试在有异常的情况下选举是否正常。
- 先产生一个
leader,然后让这个leader离线,检查集群能否再产生一个leader。 - 令原来的
leader上线,检查leader不应该发生变化。 - 令一个
leader和一个follower离线,检查此时集群不应该再产生新leader。
- 先产生一个
- 测试在有异常的情况下选举是否正常。
1.2 定义
根据论文定义raft的变量和状态变化。为了方便debug,这里定义了一个log方法来打印日志和当前raft节点的信息。
这里需要注意的是,我们用heartbeatTime来代表一个raft节点上一次收到心跳的时间,用electionTimeout来代表随机生成的超时时间。因为在每次reset的时候,他们都需要同时被设置,所以新增了一个timeMutex来保证原子性。
type NodeType string
const (
Follower NodeType = "Follower"
Candidate NodeType = "Candidate"
Leader NodeType = "Leader"
)
//
// A Go object implementing a single Raft peer.
//
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
// Persistent state on all servers
currentTerm int
votedFor int
logs []LogEntry
// Volatile state on all servers
committedIndex int
lastApplied int
// Volatile state on leaders
nextIndex []int
matchIndex []int
// other
role NodeType
timeMutex sync.Mutex
electionTimeout time.Duration
heartbeatTime time.Time
applyCh chan ApplyMsg
}
type LogEntry struct {
Term int
Command interface{}
}
func (rf *Raft) getLastLogIndex() int {
return len(rf.logs) - 1
}
func (rf *Raft) commitLogs() {
for i := rf.lastApplied + 1; i <= rf.committedIndex; i++ {
rf.printf("commit index=%d,command=%v",i,rf.logs[i].Command)
rf.applyCh <- ApplyMsg{CommandValid: true, CommandIndex: i, Command: rf.logs[i].Command}
}
rf.lastApplied = rf.committedIndex
}
func (rf *Raft) updateLeaderCommittedIndex() {
tmp := make([]int, len(rf.matchIndex))
copy(tmp, rf.matchIndex)
sort.Ints(tmp)
index := tmp[len(tmp)/2]
if rf.logs[index].Term == rf.currentTerm {
// Leader 不能提交之前任期的日志,只能通过提交自己任期的日志,从而间接提交之前任期的日志
if index > rf.committedIndex{
rf.committedIndex = tmp[len(tmp)/2]
rf.commitLogs()
rf.broadcast()
}
}
}
func (rf *Raft) convertToFollower(newTerm int) {
rf.currentTerm = newTerm
rf.votedFor = -1
rf.role = Follower
rf.printf("convert to follower")
}
func (rf *Raft) convertToCandidate() {
rf.currentTerm++
rf.votedFor = rf.me
rf.role = Candidate
rf.printf("convert to candidate")
}
func (rf *Raft) convertToLeader() {
rf.role = Leader
for j := 0; j < len(rf.peers); j++ {
if j == rf.me {
continue
}
rf.nextIndex[j] = rf.getLastLogIndex() + 1
rf.matchIndex[j] = 0
}
rf.broadcast()
rf.printf("convert to leader,%v",rf.nextIndex)
}
func (rf *Raft) resetTime() {
rf.timeMutex.Lock()
defer rf.timeMutex.Unlock()
//rf.printf("reset time")
rf.heartbeatTime = time.Now()
rf.electionTimeout = time.Millisecond * time.Duration(250+rand.Intn(250))
}
// return currentTerm and whether this server
// believes it is the leader.
func (rf *Raft) GetState() (int, bool) {
term := rf.currentTerm
isLeader := rf.role == Leader
// Your code here (2A).
return term, isLeader
}
Figure 2 提到,log 的 first index is 1,这里进行一个取巧的做法,在初始化 log 的时候先插入一条term=0的记录。基于这个规则,我定义了一个getLastLogIndex方法,来提高代码的可读性。
func (rf *Raft) getLastLogIndex() int {
return len(rf.logs) - 1
}
1.3 RequestVote PRC
RequestVote RPC 根据图2的流程书写即可。
// =======================================
// RequestVote RPC
// =======================================
type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int // candidate’s Term
CandidateId int // candidate requesting vote
LastLogIndex int // index of candidate’s last log entry
LastLogTerm int // Term of candidate’s last log entry
}
type RequestVoteReply struct {
// Your data here (2A).
Term int // currentTerm, for candidate to update itself
VoteGranted bool // true means candidate received vote
}
// RequestVote RPC handler.
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
if args.Term < rf.currentTerm {
reply.VoteGranted = false
return
}
// If RPC request or response contains term T > currentTerm, set currentTerm = T, convert to follower (§5.1)
if args.Term > rf.currentTerm {
rf.convertToFollower(args.Term)
}
if rf.votedFor == -1 || rf.votedFor == args.CandidateId {
// check log up-to-date
lastIndex := rf.getLastLogIndex()
lastTerm := rf.logs[lastIndex].Term
if lastTerm > args.LastLogTerm || (lastTerm == args.LastLogTerm && lastIndex > args.LastLogIndex) {
reply.VoteGranted = false
return
} else {
rf.printf("grand vote to %d", args.CandidateId)
reply.VoteGranted = true
rf.votedFor = args.CandidateId
}
}else{
reply.VoteGranted = false
return
}
rf.resetTime()
}
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
return ok
}
AppendEntriesRPC的具体实现参考PartB部分
1.4 状态机与ticket协程
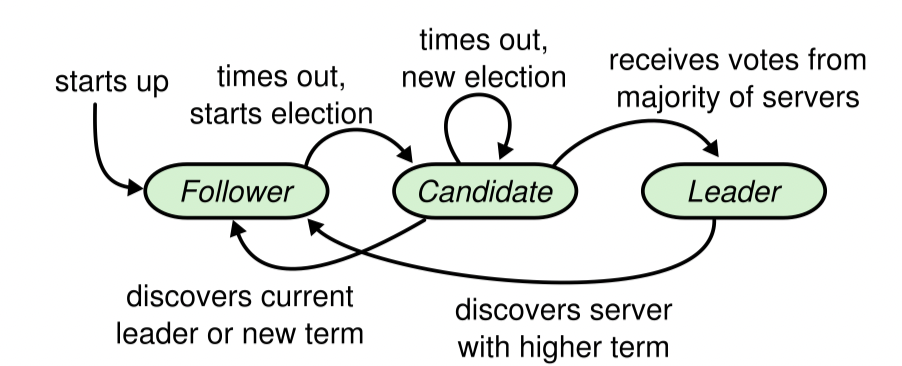
根据图4的状态机,为不同的role定义不同的行为
核心逻辑为ticker,我们为每个raft服务在初始化时启动一个ticket协程
- 如果为Leader,只需定时发送心跳即可
- 如果为Candidate或Follower,超时以后主动发起选举
func (rf *Raft) ticker() {
for rf.killed() == false {
if rf.role == Leader {
// TODO:发送心跳包
} else {
time.Sleep(time.Millisecond * 10)
rf.timeMutex.Lock()
// check heartbeats time
timeout := time.Since(rf.heartbeatTime) > rf.electionTimeout
rf.timeMutex.Unlock()
if timeout&&rf.role != Leader {
rf.startElection()
} else {
continue
}
}
}
}
func (rf *Raft) startElection() {
rf.printf("start election")
rf.mu.Lock()
defer rf.mu.Unlock()
rf.convertToCandidate()
args := RequestVoteArgs{
CandidateId: rf.me,
Term: rf.currentTerm,
LastLogIndex: rf.getLastLogIndex(),
LastLogTerm: rf.logs[rf.getLastLogIndex()].Term,
}
votedCount := 1
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
// no need to request itself
continue
}
go func(serverNum int, args RequestVoteArgs) {
reply := RequestVoteReply{VoteGranted: false}
ok := rf.sendRequestVote(serverNum, &args, &reply)
if ok && args.Term==rf.currentTerm{
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.role == Candidate && reply.VoteGranted {
// 如果同意
votedCount++
rf.printf("receive vote from %d",serverNum)
if votedCount >= len(rf.peers)/2+1{
// 当选leader
rf.convertToLeader()
}
} else if !reply.VoteGranted {
// 如果不同意
if reply.Term > rf.currentTerm {
rf.convertToFollower(reply.Term)
}
}
}
}(i, args)
}
rf.resetTime()
}
//
// the service or tester wants to create a Raft server. the ports
// of all the Raft servers (including this one) are in peers[]. this
// server's port is peers[me]. all the servers' peers[] arrays
// have the same order. persister is a place for this server to
// save its persistent state, and also initially holds the most
// recent saved state, if any. applyCh is a channel on which the
// tester or service expects Raft to send ApplyMsg messages.
// Make() must return quickly, so it should start goroutines
// for any long-running work.
//
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here (2A, 2B, 2C).
rf.logs = make([]LogEntry, 0, 0)
rf.currentTerm = 0
rf.votedFor = -1
rf.committedIndex = 0
rf.lastApplied = 0
rf.applyCh = applyCh
rf.votedFor = -1
rf.role = Follower
rf.resetTime()
rf.matchIndex = make([]int, len(peers), len(peers))
rf.nextIndex = make([]int, len(peers), len(peers))
rf.logs = append(rf.logs, LogEntry{Term: 0})
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
go rf.ticker()
return rf
}
1.5 总结
PartA的逻辑较为简单,主要难点在于重设心跳时间的实际。如果这里出现了错误,很可能出现一种活锁,例如没有leader正在被选举,或者一旦一个leader被选出来,某个其他节点又启动一轮选举,强制最近刚选出来的leader立即退位。
我在助教写的指南中明确写道,你应该仅重启你的选举定时器,如果
- a) 你收到一个来自当前 leader的
AppendEntriesRPC(即,如果AppendEntries参数中的term过期了,你就不 应该重置你的定时器); - b) 你正在开启一轮选举;
- 或者 c)你给另一个peer投 票。
如果只实现RequestVoteRPC也可以通过测试,但是会有warming,因为没有心跳的存在,一个leader当选后其他raft节点无法感知,很快又会发起新一轮选举。
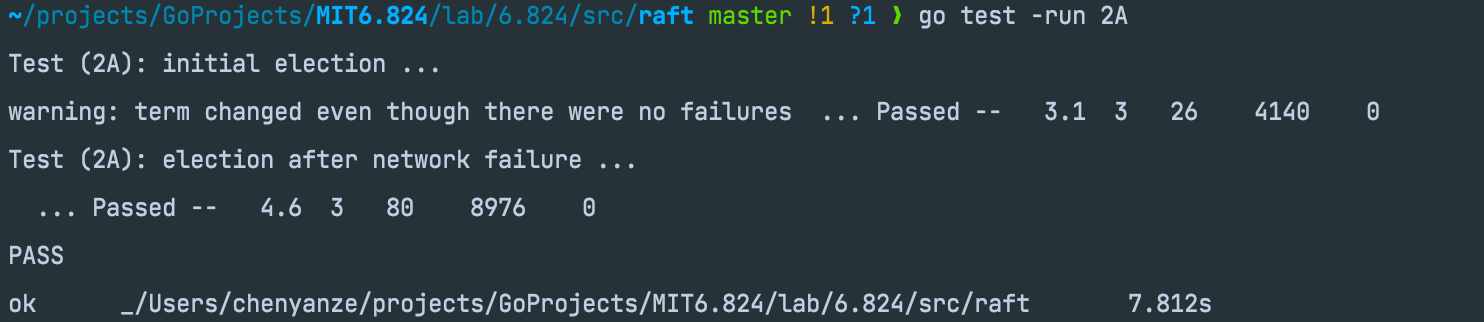
解决方案就是实现一个最基本的AppendEntriesRPC来实现心跳,具体实现将放在partB中进行。
2 PartB-日志复制
2.1 测试分析
partB的测试用例相比partA丰富了很多,在实现的过程中通过测试用例修复了非常多bug。
其中,前几个测试的逻辑都比较简单,基本都是选主➡️提交日志➡️检查日志➡️节点失联➡️节点重连等一系列流程。
最后一个测试则是检查RPC的数量,换言之就是限制了心跳的频率,如果挂在了TestCount2B,基本只需要修改心跳频率即可。
2.2 Leader Append 日志
func (rf *Raft) Start(command interface{}) (int, int, bool) {
rf.mu.Lock()
defer rf.mu.Unlock()
// Your code here (2B).
if rf.role != Leader {
return -1, -1, false
} else {
rf.logs = append(rf.logs, LogEntry{Term: rf.currentTerm, Command: command})
index := rf.getLastLogIndex()
term := rf.currentTerm
rf.matchIndex[rf.me] = index
rf.printf("append new command whose index=%d, term=%d", index, term)
rf.broadcast()
return index, term, true
}
}
2.3 AppendEntries RPC
PartB主要实现就是AppendEntriesRPC,基本上只要参考论文图2的伪代码进行实现即可。
⚠️图2右下角的Rules for Servers也需要考虑!
⚠️实现的AppendEntriesRPC在图2的基础上增加了快速回退技术
这里有个需要注意的细节是,RPC可能不是按顺序到达的,即raft server可能收到很早以前的RPC,所以一定要严格按照图2的流程。
// =======================================
// AppendEntries RPC
// =======================================
type AppendEntriesArgs struct {
Term int // leader's Term
LeaderId int // so follower can redirect clients
PrevLogIndex int // index of log entry immediately preceding
PrevLogTerm int // Term of prevLogIndex entry
Entries []LogEntry //log entries to store (empty for heartbeat; may send more than one for efficiency)
LeaderCommit int // new ones leader’s commitIndex
}
type AppendEntriesReply struct {
Term int // currentTerm, for leader to update itself
Success bool // true if follower contained entry matching prevLogIndex and prevLogTerm
// 以下为新增字段,用于快速回退
XTerm int // 与Leader冲突的Log对应的任期号; 如果Follower在对应位置没有Log,那么这里会返回 -1
XIndex int // 对应任期号为XTerm的第一条Log条目的槽位号
XLen int // XLen表示Follower最后一条的Log的Index
}
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
// 1. Reply false if Term < currentTerm
if args.Term < rf.currentTerm {
rf.printf("term mismatch %d",args.Term)
reply.Success = false
reply.Term = rf.currentTerm
reply.XTerm = XTermNoUse
return
}
rf.resetTime()
// If RPC request or response contains term T > currentTerm, set currentTerm = T, convert to follower (§5.1)
if args.Term > rf.currentTerm {
rf.convertToFollower(args.Term)
}
if rf.role==Candidate&&args.Term>=rf.currentTerm{
rf.convertToFollower(args.Term)
}
// 2. Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm
if rf.getLastLogIndex() < args.PrevLogIndex {
reply.Success = false
reply.Term = rf.currentTerm
reply.XTerm = -1
reply.XLen = rf.getLastLogIndex()
return
}else if rf.getLastLogIndex() >= args.PrevLogIndex && rf.logs[args.PrevLogIndex].Term != args.PrevLogTerm{
reply.Success = false
reply.Term = rf.currentTerm
reply.XTerm = rf.logs[args.PrevLogIndex].Term
for i:=args.PrevLogIndex;i>=0&&rf.logs[i].Term==reply.XTerm;i--{
reply.XIndex = i
}
return
}
// 3. If an existing entry conflicts with a new one (same index but different terms),
// delete the existing entry and all that follow it
startAppendIndex := 0
for ; startAppendIndex<len(args.Entries)&&args.PrevLogIndex+1+startAppendIndex<len(rf.logs); startAppendIndex++{
if rf.logs[args.PrevLogIndex+1+startAppendIndex].Term!=args.Entries[startAppendIndex].Term{
rf.logs = rf.logs[:args.PrevLogIndex+1+startAppendIndex]
break
}
}
// 4. Append any new entries not already in the log
rf.logs = append(rf.logs, args.Entries[startAppendIndex:]...)
// 5. If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
if args.LeaderCommit > rf.committedIndex {
if args.LeaderCommit <= rf.getLastLogIndex() {
rf.committedIndex = args.LeaderCommit
} else {
rf.committedIndex = rf.getLastLogIndex()
}
rf.commitLogs()
}
rf.printf("append entries, last index=%d, last term=%d",rf.getLastLogIndex(),rf.logs[rf.getLastLogIndex()].Term)
reply.Term = rf.currentTerm
reply.Success = true
rf.resetTime()
}
2.4 广播
AppendEntries RPC用于心跳和日志复制。实际上,心跳可以看作是定时发送的AppendEntriesRPC,不需要特殊考虑,只需要在Raft Server的ticket协程中每隔一段时间进行一次广播即可。因此,我们实现一个broadcast方法作为Raft向其他节点群发AppendEntriesRPC的入口。
func (rf *Raft) broadcast() {
for i := range rf.peers {
if i==rf.me{
continue
}
// send heartbeat
args := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
LeaderCommit: rf.committedIndex,
}
args.PrevLogIndex = rf.nextIndex[i] - 1
args.PrevLogTerm = rf.logs[args.PrevLogIndex].Term
if rf.nextIndex[i] < len(rf.logs) {
args.Entries = rf.logs[rf.nextIndex[i]:]
}
go func(serverNum int, args AppendEntriesArgs) {
reply := AppendEntriesReply{}
ok := rf.sendAppendEntries(serverNum, &args, &reply)
if ok {
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term > rf.currentTerm {
rf.convertToFollower(reply.Term)
return
}
if rf.role!=Leader{
return
}
if !reply.Success {
// 这里如果使用默认的回退策略,不能直接--,否则如果两个heartbeat一起返回,会-2,跳过了正常的。
//rf.nextIndex[serverNum] = args.PrevLogIndex
// 快速回退
rf.printf("broadcast receive fail, XTerm=%d, XLen=%d, XIndex=%d",reply.XTerm,reply.XLen,reply.XIndex)
if reply.XTerm==-1{
rf.nextIndex[serverNum] = reply.XLen+1
}else if reply.XTerm!=XTermNoUse{
if rf.logs[reply.XIndex].Term==reply.Term{
rf.nextIndex[serverNum] = reply.XIndex+1
}else{
rf.nextIndex[serverNum] = reply.XIndex
}
}
rf.printf("update nextIndex %v",rf.nextIndex)
}
if reply.Success {
rf.matchIndex[serverNum] = args.PrevLogIndex + len(args.Entries)
rf.nextIndex[serverNum] = rf.matchIndex[serverNum]+1
rf.updateLeaderCommittedIndex()
}
}
}(i, args)
}
}
func (rf *Raft) ticker() {
for rf.killed() == false {
if rf.role == Leader {
rf.broadcast()
time.Sleep(time.Millisecond * 50)
} else {
time.Sleep(time.Millisecond * 10)
rf.timeMutex.Lock()
// check heartbeats time
timeout := time.Since(rf.heartbeatTime) > rf.electionTimeout
rf.timeMutex.Unlock()
if timeout&&rf.role != Leader {
rf.startElection()
} else {
continue
}
}
}
}
2.5 日志提交
commitLogs供Leader和Follower来提交日志。Follower提交日志的规则很简单,只需要根据接收到的AppendEntires RPC中的LeaderCommit参数进行commit即可。
func (rf *Raft) commitLogs() {
for i := rf.lastApplied + 1; i <= rf.committedIndex; i++ {
rf.printf("commit index=%d,command=%v",i,rf.logs[i].Command)
rf.applyCh <- ApplyMsg{CommandValid: true, CommandIndex: i, Command: rf.logs[i].Command}
}
rf.lastApplied = rf.committedIndex
}
Leader根据matchIndex来决定提交哪些日志,只需超过半数的节点matchIndex>N,且term(N)=currentTerm,就可以提交日志。实现上可以直接对matchIndex排序来找到最大可提交的committedIndex。
func (rf *Raft) updateLeaderCommittedIndex() {
tmp := make([]int, len(rf.matchIndex))
copy(tmp, rf.matchIndex)
sort.Ints(tmp)
index := tmp[len(tmp)/2]
if rf.logs[index].Term == rf.currentTerm {
// Leader 不能提交之前任期的日志,只能通过提交自己任期的日志,从而间接提交之前任期的日志
if index > rf.committedIndex{
rf.committedIndex = tmp[len(tmp)/2]
rf.commitLogs()
rf.broadcast()
}
}
}
2.6 测试踩坑&优化&总结
PartB的实现有很多可优化点,上述代码为优化后的代码,但仍有很多可优化之处,后续进行改进。
测试方法为执行
time go test -run 2B,具体参考实验手册
踩坑:心跳间隔
理论上,一定程度上心跳间隔越短,性能应该是越好的。
func (rf *Raft) ticker() {
for rf.killed() == false {
if rf.role == Leader {
rf.broadcast()
time.Sleep(time.Millisecond * 150) // modify here
} else {
time.Sleep(time.Millisecond * 10)
rf.timeMutex.Lock()
// check heartbeats time
timeout := time.Since(rf.heartbeatTime) > rf.electionTimeout
rf.timeMutex.Unlock()
if timeout&&rf.role != Leader {
rf.startElection()
} else {
continue
}
}
}
}
一开始,我尝试将心跳间隔缩短到50ms,能够大幅缩短测试时间,且测试大概率能过通过。但在大量测试下,有小概率情况会无法通过TestCount2B。
Lab实验手册中写到,Because the tester limits you to 10 heartbeats per second,理想的间隔应为100ms。但考虑到除心跳外还可能有其他RPC,所以一个比较合适的时间间隔应为150ms,为了保证在electionTime内收到心跳,需要相应更改心跳超时为250~500ms随机(论文为150~300ms随机)。
优化一:Leader append日志后立即进行一次广播
上述代码皆为优化后的代码,此处仅为优化过程复盘。
实验手册中提到,If your solution uses much more than a minute of real time for the 2B tests, or much more than 5 seconds of CPU time, you may run into trouble later on.
未优化之前,运行时间不符合要求。
Test (2B): basic agreement ...
... Passed -- 1.2 3 18 5106 3
Test (2B): RPC byte count ...
... Passed -- 3.5 3 48 114394 11
Test (2B): agreement despite follower disconnection ...
... Passed -- 6.5 3 106 27894 8
Test (2B): no agreement if too many followers disconnect ...
... Passed -- 3.7 5 180 35602 3
Test (2B): concurrent Start()s ...
... Passed -- 0.8 3 12 3406 6
Test (2B): rejoin of partitioned leader ...
... Passed -- 6.8 3 146 36354 4
Test (2B): leader backs up quickly over incorrect follower logs ...
... Passed -- 48.5 5 2876 2063884 106
Test (2B): RPC counts aren't too high ...
... Passed -- 2.3 3 32 9552 12
PASS
ok _/Users/chenyanze/projects/GoProjects/MIT6.824/lab/6.824/src/raft 76.934s
go test -run 2B 1.49s user 0.80s system 2% cpu 1:17.11 total
考虑到Leader append日志后,如果不立即发送广播,将会等到下次发送心跳的时候一并发送。Start()方法为Leader append日志到Leader发送心跳的这段时间实际上是浪费的,因此可以考虑在Start()方法为Leader append日志后立即发送一轮广播。
func (rf *Raft) Start(command interface{}) (int, int, bool) {
rf.mu.Lock()
defer rf.mu.Unlock()
// Your code here (2B).
if rf.role != Leader {
return -1, -1, false
} else {
rf.logs = append(rf.logs, LogEntry{Term: rf.currentTerm, Command: command})
index := rf.getLastLogIndex()
term := rf.currentTerm
rf.matchIndex[rf.me] = index
rf.printf("append new command whose index=%d, term=%d", index, term)
rf.broadcast() // 立即发送广播
return index, term, true
}
}
优化后,测试时间显著变短!😄
Test (2B): basic agreement ...
... Passed -- 0.7 3 18 5142 3
Test (2B): RPC byte count ...
... Passed -- 1.9 3 50 114974 11
Test (2B): agreement despite follower disconnection ...
... Passed -- 4.2 3 86 22751 7
Test (2B): no agreement if too many followers disconnect ...
... Passed -- 3.6 5 200 40336 3
Test (2B): concurrent Start()s ...
... Passed -- 0.5 3 22 6754 6
Test (2B): rejoin of partitioned leader ...
... Passed -- 4.1 3 112 26377 4
Test (2B): leader backs up quickly over incorrect follower logs ...
... Passed -- 33.6 5 2736 2024142 107
Test (2B): RPC counts aren't too high ...
... Passed -- 2.1 3 52 17508 12
PASS
ok _/Users/chenyanze/projects/GoProjects/MIT6.824/lab/6.824/src/raft 50.837s
go test -run 2B 1.44s user 0.66s system 4% cpu 51.103 total
优化二:Leader commit日志后立即进行一次广播
有了上述经验,我再次考虑到,Leader commit一条日志后,实际上也要等到下次发送心跳的时候才会告知其他Follower节点,Follower节点才会提交。也就是说,Leader commit日志到Leader发送心跳的这段时间内,Follower节点是无法感知到最新日志的提交的。
在实际的生产中,这个点应该是没有影响的,因为一旦Leader commit后,Leader可以立即反馈给client。但在Lab中,测试用例会对所有节点的commit情况进行检查。因此,可以考虑在这里进行一次优化。
func (rf *Raft) updateLeaderCommittedIndex() {
tmp := make([]int, len(rf.matchIndex))
copy(tmp, rf.matchIndex)
sort.Ints(tmp)
index := tmp[len(tmp)/2]
if rf.logs[index].Term == rf.currentTerm {
// Leader 不能提交之前任期的日志,只能通过提交自己任期的日志,从而间接提交之前任期的日志
if index > rf.committedIndex{
rf.committedIndex = tmp[len(tmp)/2]
rf.commitLogs()
rf.broadcast() // 立即发送广播
}
}
}
优化后,测试时间再一次变短!😄
Test (2B): basic agreement ...
... Passed -- 0.3 3 18 5185 3
Test (2B): RPC byte count ...
... Passed -- 0.6 3 54 166125 11
Test (2B): agreement despite follower disconnection ...
... Passed -- 3.8 3 90 24183 7
Test (2B): no agreement if too many followers disconnect ...
... Passed -- 3.3 5 200 41302 4
Test (2B): concurrent Start()s ...
... Passed -- 0.6 3 28 8576 6
Test (2B): rejoin of partitioned leader ...
... Passed -- 5.6 3 146 36798 4
Test (2B): leader backs up quickly over incorrect follower logs ...
... Passed -- 19.2 5 2224 1544358 106
Test (2B): RPC counts aren't too high ...
... Passed -- 2.2 3 58 19778 12
PASS
ok _/Users/chenyanze/projects/GoProjects/MIT6.824/lab/6.824/src/raft 38.641s
go test -run 2B 1.31s user 0.56s system 4% cpu 38.904 total
优化三:快速回退
在视频中,Morris教授提到了“快速回退nextIndex”技术,可以更快地定位到正确的nextIndex。
在测试中,我发现如果不使用快速回退技术,会有极少数情况(大概每60次测试出现一次)无法通过用例TestBackup2B。
原因在于最原始的策略为每次AppendEntires失败就将nextIndex-1,这有时候需要大量的RPC用于回退nextIndex,而nextIndex每次回退以后又需要等待下一次广播(或许是心跳触发,或许是其他触发)才能进行AppendEntriesRPC的尝试。
使用快速回退技术以后,测试时间再一次变短,且测试300+次均PASS!😄
Test (2B): basic agreement ...
... Passed -- 0.4 3 18 5185 3
Test (2B): RPC byte count ...
... Passed -- 0.5 3 52 165807 11
Test (2B): agreement despite follower disconnection ...
... Passed -- 3.0 3 78 20936 7
Test (2B): no agreement if too many followers disconnect ...
... Passed -- 3.3 5 200 40556 4
Test (2B): concurrent Start()s ...
... Passed -- 0.5 3 30 9180 6
Test (2B): rejoin of partitioned leader ...
... Passed -- 3.6 3 116 28146 4
Test (2B): leader backs up quickly over incorrect follower logs ...
... Passed -- 6.7 5 1652 1104607 102
Test (2B): RPC counts aren't too high ...
... Passed -- 2.2 3 58 20009 12
PASS
ok _/Users/chenyanze/projects/GoProjects/MIT6.824/lab/6.824/src/raft 21.104s
go test -run 2B 1.05s user 0.43s system 6% cpu 21.366 total
未优化
还有可优化点在PartB中未实现:
- 我对每个AppendEntriesRPC的参数都带上了LogEntries。实际上,如果Leader对某个Follower的nextIndex不是正确的,AppendEntriesRPC会返回false,此时RPC所携带的LogEntries数据会浪费很多网络资源,这里可以优化默认不带LogEntries,如果返回true,再立即重发一个带LogEntries的AppendEntriesRPC。
- 预投票,防止网络分区下term暴增。
总结
至此,PartB结束。
经过300+次测试均PASS,测试耗时约20s+(小于实验手册中要求的1min),CPU用时约0.4s+(小于实验手册中要求的5s)!
3 PartC-持久化
part c 中只需实现 persist和readPersist,并在正确的位置进行持久化即可。
//
// save Raft's persistent state to stable storage,
// where it can later be retrieved after a crash and restart.
// see paper's Figure 2 for a description of what should be persistent.
//
func (rf *Raft) persist() {
// Your code here (2C).
// Example:
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.logs)
data := w.Bytes()
rf.persister.SaveRaftState(data)
}
//
// restore previously persisted state.
//
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
// Your code here (2C).
// Example:
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm int
var votedFor int
var logs []LogEntry
if d.Decode(¤tTerm) != nil ||
d.Decode(&votedFor) != nil ||
d.Decode(&logs) != nil {
rf.printf("error decode ")
} else {
rf.currentTerm = currentTerm
rf.votedFor = votedFor
rf.logs = logs
}
}
难点在于,PartC的测试十分复杂,可能发现前面隐藏的bug。
总结
经过一周多的努力,实现了整个lab2,经过300+次的测试均无bug。
在调试的过程中,很多bug都是需要测试数十次才能复现。而每次测试需要两分多种,因此在测试上花费了大量的实现。复盘来看,遇到的bug主要和term混淆、选举超时设置时间相关,或是没有完全按照figure2的流程来实现,这些错误实际上都可以在助教写的手册中找到(中文翻译:https://zhuanlan.zhihu.com/p/203279804)。
最后附上一张测试通过的截图,整个测试流程花费了近15个小时。