Lab1 MapReduce
0 简介
Lab1实现了一个执行Wordcount任务的MapReduce,需要阅读论文MapReduce
我在实现的过程中使用了go的chan和atomic替代显示的锁操作(Mutex),本文记录实现部分介绍我从零开始实现的过程,文中所附的部分代码并非最终版本,而是实现过程中的一些“快照”,完整代码可参考本人GitHub仓库:https://github.com/Cpaulyz/MIT6.824
不保证完全的 bug free,但经过100+次的测试均通过,测试脚本见“结果验证”章节的测试脚本。
1 环境搭建
- 实验环境:macOS Monterer (m1)
- 实验手册:2020版实验,http://nil.csail.mit.edu/6.824/2020/labs/lab-mr.html
直接 brew install go 即可,go version 为 go1.17.4 darwin/arm64
按照实验手册的指导,下载代码
$ git clone git://g.csail.mit.edu/6.824-golabs-2020 6.824
$ cd 6.824
$ cd src/main
$ go build -buildmode=plugin ../mrapps/wc.go
$ rm mr-out*
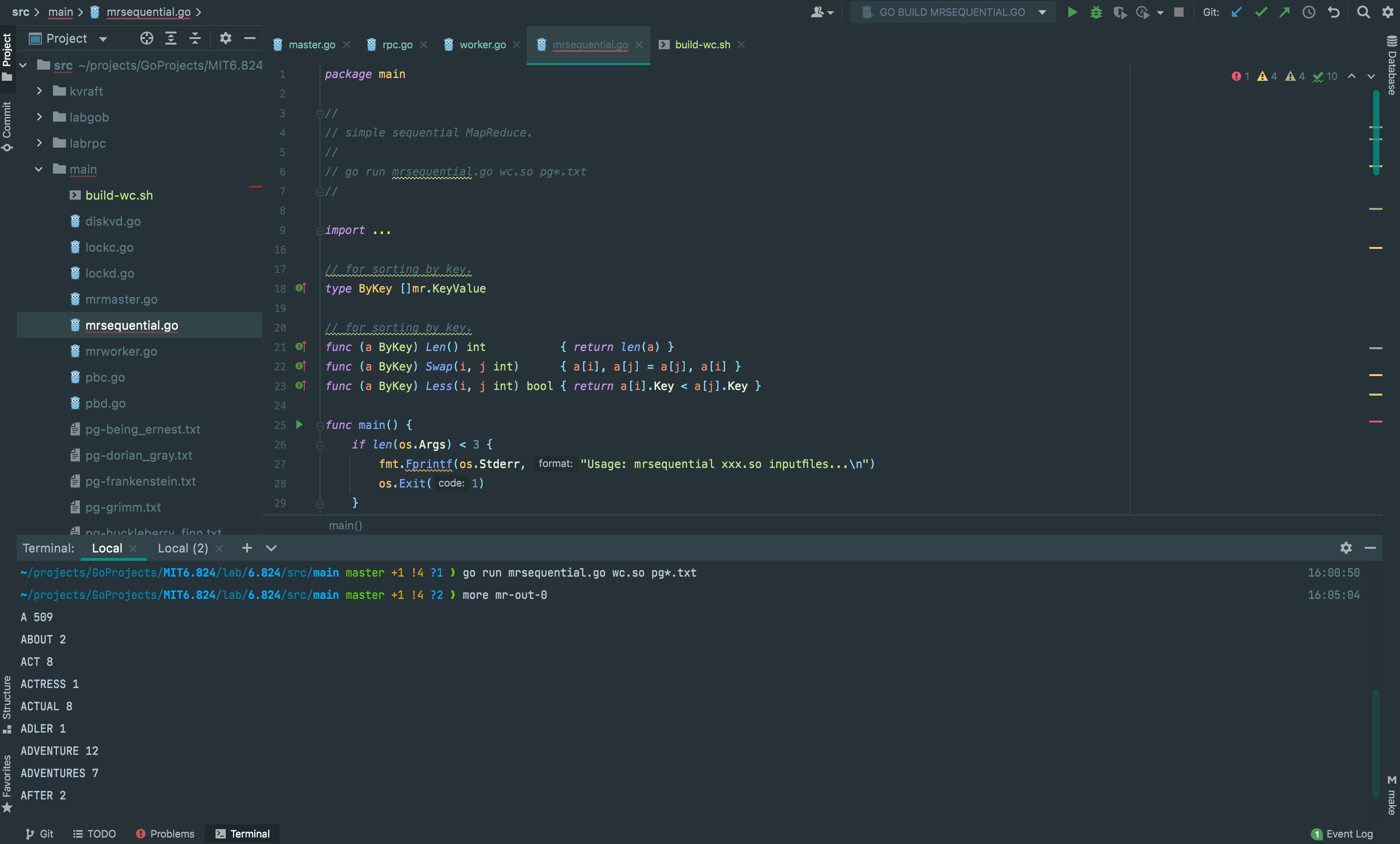
$ go run mrsequential.go wc.so pg*.txt
$ more mr-out-0
A 509
ABOUT 2
ACT 8
...
本人在 GoLand IDE 中进行开发,使用命令行运行
为方便debug,写了一个shell脚本进行环境清理以及build
#!bin/bash
# build-wc.s
rm -rf mr-*
go build -buildmode=plugin ../mrapps/wc.go
因为test-mr.sh脚本中有 timeout 指令,而macOS下没有而引发的 command not found 错误,可以参考:https://segmentfault.com/q/1010000011541227
2 结构分析
本次实验只需要修改三个文件:mr/worker.go, mr/master.go, and mr/rpc.go
- rpc:在该文件下定义rpc调用的请求体和返回题
- master:实现master的功能,包括分配task、接受worker完成任务后的回调等
- worker:根据给定的mapfunc和reducefunc,运行由 master 分配下来的 map task 和 reduce task,并通过 rpc 通知 master 任务是否完成
其中,rpc部分一开始令我比较费解,在此进行记录:
实际上,实验代码已经为我们定义好了rpc框架,并给出了一个具体的Example,忽略框架性的代码,可以看到定义一个RPC的流程分为3步:
- 在
rpc.go中定义请求体和返回题 - 在被调用方实现Handler,根据请求参数计算返回值
- 在调用方(实验中均为worker)中调用框架给出的call,传入Handler、请求体、返回体即可
// master.go
func (m *Master) Example(args *ExampleArgs, reply *ExampleReply) error {
reply.Y = args.X + 1
return nil
}
// rpc.go
// the RPC argument and reply types are defined in rpc.go.
type ExampleArgs struct {
X int
}
type ExampleReply struct {
Y int
}
// worker.go
func CallExample() {
// declare an argument structure.
args := ExampleArgs{}
// fill in the argument(s).
args.X = 99
// declare a reply structure.
reply := ExampleReply{}
// send the RPC request, wait for the reply.
call("Master.Example", &args, &reply)
// reply.Y should be 100.
fmt.Printf("reply.Y %v\n", reply.Y)
}
3 实现
3.1 Task分配
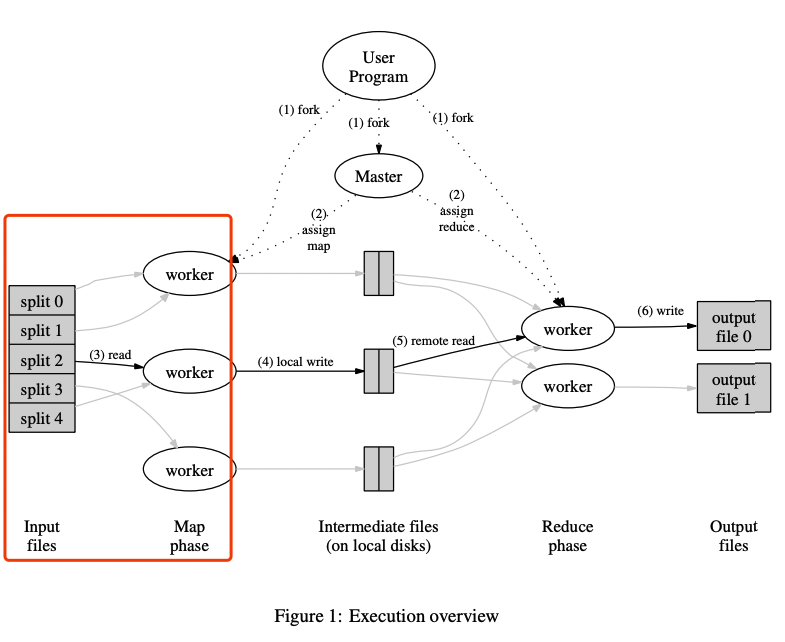
根据hint我们可以得到一些启发——该实验可以从Task的分配入手
One way to get started is to modify
mr/worker.go'sWorker()to send an RPC to the master asking for a task. Then modify the master to respond with the file name of an as-yet-unstarted map task. Then modify the worker to read that file and call the application Map function, as inmrsequential.go.
3.1.1 Master定义
参考论文中的“Master Data Structures”(The master keeps several data structures. For each map task and reduce task, it stores the state (idle, in-progress, or completed), and the identity of the worker machine (for non-idle tasks).),定义master结构体如下:
// mr/master.go
type TaskStatus int8
const (
IDLE TaskStatus = 0
InProcess TaskStatus = 1
Completed TaskStatus = 2
)
type Master struct {
// Your definitions here.
MapNum int
ReduceNum int
FileNames []string // it has MapNum items
MapStatus []TaskStatus // it has MapNum items
ReduceStatus []TaskStatus // it has ReduceNum items
MapDone bool
ReduceDone bool
WorkerId int32 // allocate to worker
MapWorker []int // it has MapNum items
ReduceWorker []int // it has ReduceNum items
}
- 我们以
MapId([0,MapNum))和ReduceId([0,ReduceNum])来作为task的标识符,其中MapId对应第MapId个InputFIles xxxxStatus记录了map/reduce task的分配情况,xxxxWorker记录了map/reduce task的分配给了哪个workerWorkerId是一个不断自增的整数,用于WorkerId的分配xxxxWorker和WorkerId的存在原因将在错误恢复中用到,详看3.5
3.1.2 Worker定义
相应的,一个task可能为map,也可能为reduce,需要一个字段进行区分,定义的worker结构体如下
// mr/worker.go
type TaskType int8
const (
MapTask TaskType = 0
ReduceTask TaskType = 1
)
type WorkerTask struct {
WorkerId int
Type TaskType
FileName string
MapId int
ReduceId int
MapNum int
ReduceNum int
MapFunc func(string, string) []KeyValue
ReduceFunc func(string, []string) string
}
3.1.3 RPC定义
worker主动向master请求任务
这里有一个细节,使用chan来代替锁结构,但需要注意因为chan缓冲的存在,在
generateTask将task写入chan后需要立即将MapStatus/ReduceStatus改为InProcess,否则在下次循环时该task会被重复分配。
// ====================== mr/rpc.go ======================
type NoArgs struct {
}
type AllocateTaskReply struct {
WorkerId int
Type TaskType
FileName string
MapId int
ReduceId int
MapNum int
ReduceNum int
}
// ====================== mr/worker.go ======================
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
task := WorkerTask{MapFunc: mapf, ReduceFunc: reducef}
task.CallForAllocateTask()
}
func (task *WorkerTask) CallForAllocateTask() {
arg := NoArgs{}
reply := AllocateTaskReply{}
call("Master.AllocateTaskHandle", &arg, &reply)
fmt.Printf("reply %v\n", reply)
task.WorkerId = reply.WorkerId
task.Type = reply.Type
task.ReduceNum = reply.ReduceNum
task.MapNum = reply.MapNum
if task.Type == MapTask {
task.FileName = reply.FileName
task.MapId = reply.MapId
} else if task.Type == ReduceTask {
task.ReduceId = reply.ReduceId
}
}
// ====================== mr/master.go ======================
var mapAllocateId chan int
var reduceAllocateId chan int
func (m *Master) generateTask() {
for !m.MapDone {
for i, _ := range m.FileNames {
if m.MapStatus[i] == IDLE {
m.MapStatus[mapIdx] = InProcess
mapAllocateId <- i
}
}
}
for !m.ReduceDone {
for i := 0; i < m.ReduceNum; i++ {
if m.ReduceStatus[i] == IDLE {
m.ReduceStatus[reduceIdx] = InProcess
reduceAllocateId <- i
}
}
}
}
func (m *Master) AllocateTaskHandle(arg *NoArgs, reply *AllocateTaskReply) error {
select {
case mapIdx := <-mapAllocateId:
reply.FileName = m.FileNames[mapIdx]
reply.MapId = mapIdx
reply.Type = MapTask
reply.ReduceNum = m.ReduceNum
reply.MapNum = m.MapNum
reply.WorkerId = int(atomic.AddInt32(&m.WorkerId, 1))
m.MapWorker[mapIdx] = reply.WorkerId
// TODO:计时
return nil
case reduceIdx := <-reduceAllocateId:
reply.ReduceId = reduceIdx
reply.Type = ReduceTask
reply.ReduceNum = m.ReduceNum
reply.MapNum = m.MapNum
reply.WorkerId = int(atomic.AddInt32(&m.WorkerId, 1))
m.ReduceWorker[reduceIdx] = reply.WorkerId
// TODO:计时
return nil
}
}
func MakeMaster(files []string, nReduce int) *Master {
m := Master{
len(files),
nReduce,
files,
make([]TaskStatus, len(files)),
make([]TaskStatus, nReduce),
false,
false,
0,
make([]int, len(files)),
make([]int, nReduce),
}
for i, _ := range files {
m.MapStatus[i] = IDLE
}
fmt.Printf("init master %v\n", m)
// Your code here.
mapAllocateId = make(chan int, m.MapNum)
reduceAllocateId = make(chan int, m.ReduceNum)
go m.generateTask()
m.server()
return &m
}
至此,我们尝试运行,手动起master和worker,应该可以看到worker被不断分配任务


但此时的generateTask方法仍有问题,注意到一旦所有的MapStatus都为InProcess时,mapDone仍然为false,此时会陷入死循环,这就需要我们在后续让worker运行被分配的mapTask,并在完成后回调给master,通知master修改状态。
3.2 Map流程
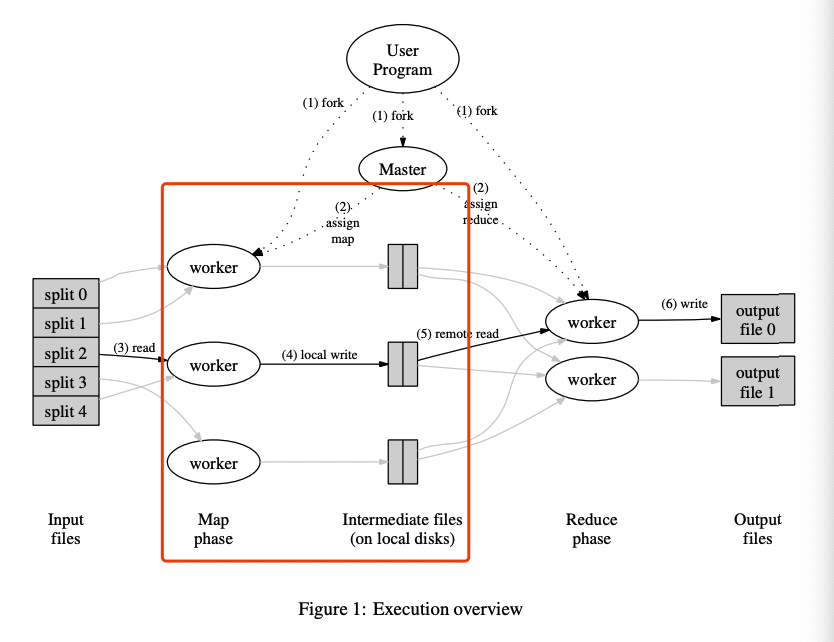
上文说道,worker被分配了map task,此时我们需要执行map task,并将中间结果写入local disks
实验手册中给出了几条有用的提示:
The worker should put intermediate Map output in files in the current directory, where your worker can later read them as input to Reduce tasks.
This lab relies on the workers sharing a file system. That’s straightforward when all workers run on the same machine, but would require a global filesystem like GFS if the workers ran on different machines.
A reasonable naming convention for intermediate files is
mr-X-Y, where X is the Map task number, and Y is the reduce task number.The worker’s map task code will need a way to store intermediate key/value pairs in files in a way that can be correctly read back during reduce tasks. One possibility is to use Go’s encoding/json package. To write key/value pairs to a JSON file:
enc := json.NewEncoder(file) for _, kv := ... { err := enc.Encode(&kv)and to read such a file back:
dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { break } kva = append(kva, kv) }The map part of your worker can use the
ihash(key)function (inworker.go) to pick the reduce task for a given key.
3.2.1 Worker执行
worker拿到task后,根据Type字段区分task类型,如果是map task,则根据Map函数执行map流程
// ====================== mr/worker.go ======================
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
task := WorkerTask{MapFunc: mapf, ReduceFunc: reducef}
task.CallForAllocateTask()
if task.Type == MapTask {
task.DoMap()
}
}
func (task *WorkerTask) DoMap() {
data, err := ioutil.ReadFile(task.FileName)
if err != nil {
fmt.Printf("file read err %s \n", task.FileName)
return
}
kvs := task.MapFunc(task.FileName, string(data))
intermediate := make([][]KeyValue, task.ReduceNum)
for _, kv := range kvs {
idx := ihash(kv.Key) % task.ReduceNum
intermediate[idx] = append(intermediate[idx], kv)
}
// write to intermediate files
for i := 0; i < task.ReduceNum; i++ {
intermediateFileName := fmt.Sprintf("mr-%d-%d", task.MapId, i)
file, fileErr := os.Create(intermediateFileName)
if fileErr != nil {
fmt.Printf("file create error %s \n", intermediateFileName)
return
}
defer file.Close()
enc := json.NewEncoder(file)
for _, kv := range intermediate[i] {
encodeErr := enc.Encode(kv)
if encodeErr != nil {
fmt.Printf("encode error %s \n", intermediate[i])
return
}
}
}
task.ReportWorkerTask(nil)
}
3.2.2 RPC
上文的最后,我们看到了一个doMap的最后调用了task.ReportWorkerTask(nil),实际上这是通过RPC通知master该map task执行成功。注意,该函数也会在后续的reduce流程中被复用。
// ====================== mr/worker.go ======================
func (task *WorkerTask) ReportWorkerTask(err error) bool {
success := true
if err != nil {
success = false
}
arg := ReportTaskArgs{task.WorkerId, task.Type, task.MapId, task.ReduceId, success}
reply := ReportTaskReply{false}
call("Master.ReportWorkerTaskHandle", &arg, &reply)
return reply.Success
}
// ====================== mr/rpc.go ======================
type ReportTaskReply struct {
Success bool
}
type ReportTaskArgs struct {
WorkerId int
Type TaskType
MapId int
ReduceId int
Success bool
}
3.2.3 Master被通知
master处理worker完成task后通过PRC发来的通知,此时需要修改TaskStatus
// ====================== mr/master.go ======================
func (m *Master) ReportWorkerTaskHandle(arg *ReportTaskArgs, reply *ReportTaskReply) error {
if arg.Type == MapTask {
if arg.Success && m.MapStatus[arg.MapId] == InProcess && m.MapWorker[arg.MapId] == arg.WorkerId {
fmt.Printf("worker %d done \n", arg.WorkerId)
m.MapStatus[arg.MapId] = Completed
isDone := true
for i := 0; i < m.MapNum; i++ {
if m.MapStatus[i] != Completed {
isDone = false
break
}
}
m.MapDone = isDone
reply.Success = true
} else { // failed
m.MapStatus[arg.MapId] = IDLE
reply.Success = false
}
} else if arg.Type == ReduceTask {
if arg.Success && m.ReduceStatus[arg.ReduceId] == InProcess && m.ReduceWorker[arg.ReduceId] == arg.WorkerId {
fmt.Printf("worker %d done \n", arg.WorkerId)
m.ReduceStatus[arg.ReduceId] = Completed
isDone := true
for i := 0; i < m.ReduceNum; i++ {
if m.ReduceStatus[i] != Completed {
isDone = false
break
}
}
m.ReduceDone = isDone
reply.Success = true
} else { // failed
m.ReduceStatus[arg.ReduceId] = IDLE
reply.Success = false
}
}
return nil
}
至此,我们尝试运行,手动起master和worker,应该可以看到worker被不断分配任务,在完成map task后会被继续分配reduce task,并且我们能在main文件夹中看到中间文件的生成
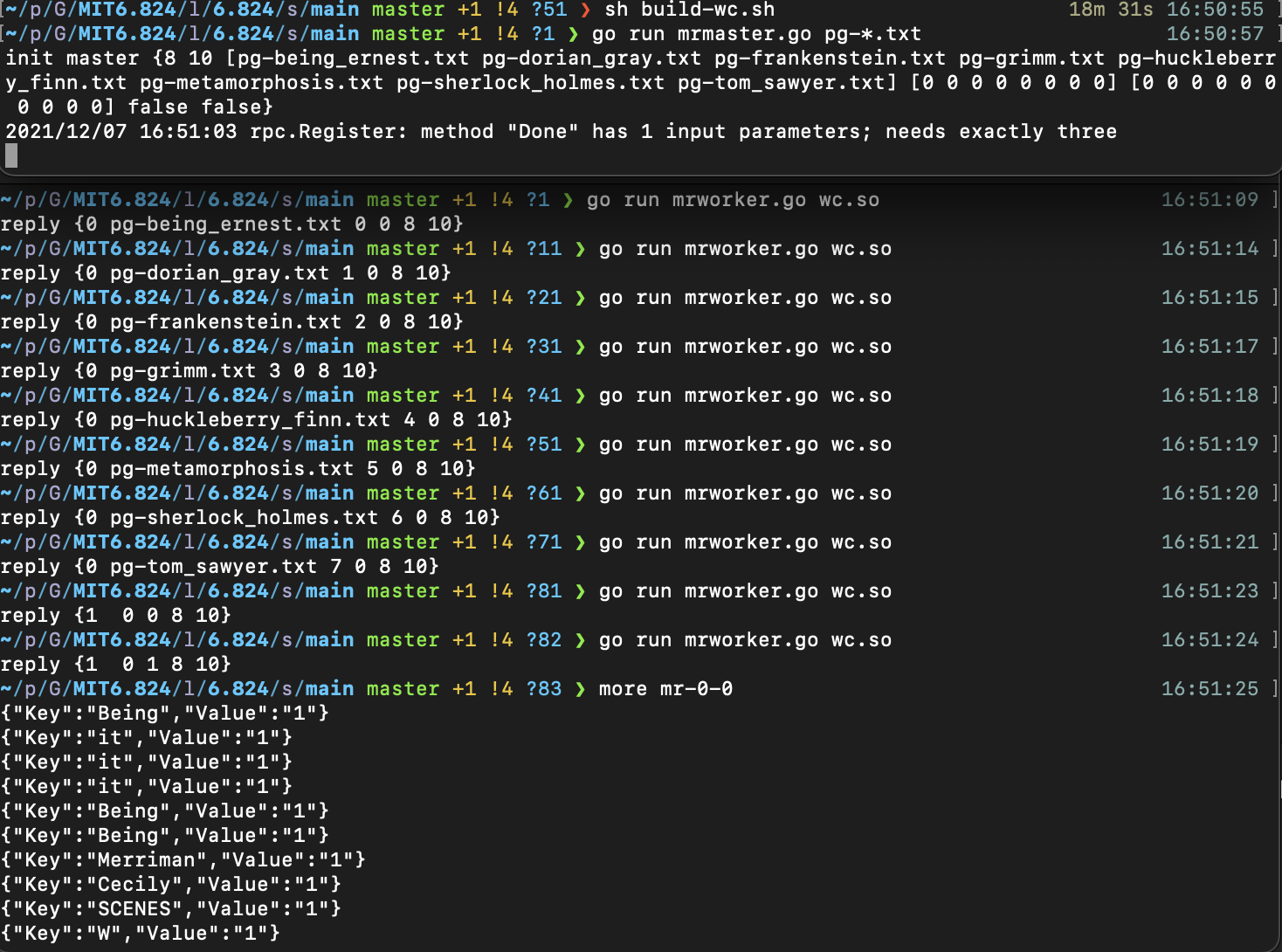
3.3 Reduce流程
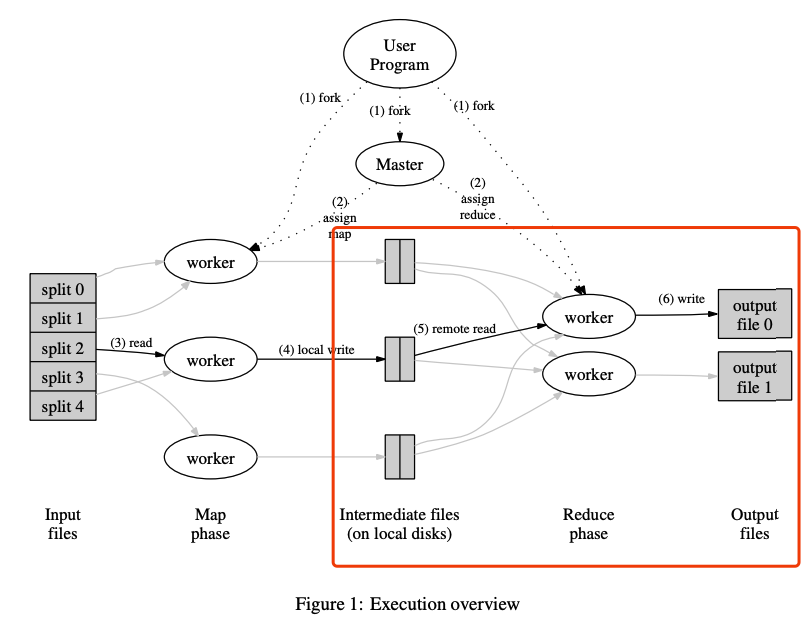
Reduce部分比较简单,和Map流程类似,我们只需要定义一个DoReduce的过程,并且在reduce完成后一样以RPC的方式通知master即可,最终输出的文件名称要按照实验手册中的严格给出
- A
mr-out-Xfile should contain one line per Reduce function output. The line should be generated with the Go"%v %v"format, called with the key and value. Have a look inmain/mrsequential.gofor the line commented “this is the correct format”. The test script will fail if your implementation deviates too much from this format.
3.3.1 Worker执行
// ====================== mr/worker.go ======================
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
task := WorkerTask{MapFunc: mapf, ReduceFunc: reducef}
task.CallForAllocateTask()
if task.Type == MapTask {
task.DoMap()
} else {
task.DoReduce()
}
}
func (task *WorkerTask) DoReduce() {
kvsMap := make(map[string][]string)
// read local disk to load intermediate file
for i := 0; i < task.MapNum; i++ {
fileName := fmt.Sprintf("mr-%d-%d", i, task.ReduceId)
file, err := os.Open(fileName)
if err != nil {
fmt.Printf("file read err %s \n", fileName)
return
}
dec := json.NewDecoder(file)
for {
var kv KeyValue
if err = dec.Decode(&kv); err != nil {
break
}
_, ok := kvsMap[kv.Key]
if !ok {
kvsMap[kv.Key] = make([]string, 0)
}
kvsMap[kv.Key] = append(kvsMap[kv.Key], kv.Value)
}
}
// reduce
outFileName := fmt.Sprintf("mr-out-%d", task.ReduceId)
outFile, _ := os.Create(outFileName)
defer outFile.Close()
for key, val := range kvsMap {
reduceRes := task.ReduceFunc(key, val)
fmt.Fprintf(outFile, "%v %v\n", key, reduceRes)
}
task.ReportWorkerTask(nil)
}
至此,我们尝试运行,手动起master和worker,在完成reduce task后我们能在main文件夹中看到最终文件的生成
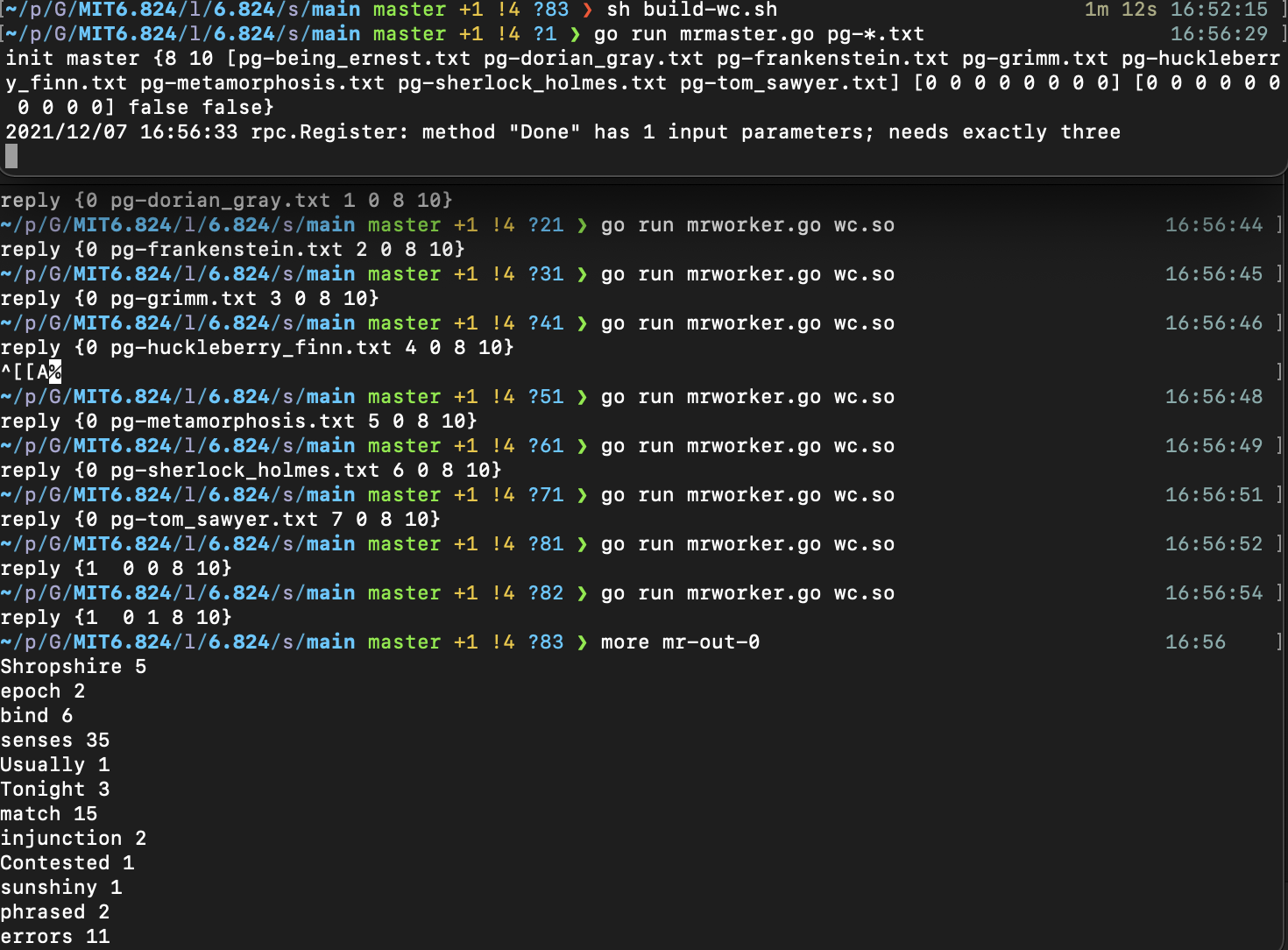
3.4 跑起来
注意到,前面的实现里面,Worker是一次性的,而Master是一直存在的,这与论文里的情况明显不符合,也不是真实的运行情况,仅仅是方便实现的一种写法。
因此,在这里需要将其改为真实的情况,我们需要做的事情有:
- Master 一直分配任务
- 当 MapTask 全部做完后,才可以分配 ReduceTask
- 当没有任务可以分配时,让 Worker 等待
- 当所有任务都做完时,让 Worker 退出
- Worker 轮询向 Master 请求任务,当所有任务做完后,Worker退出
3.4.1 Worker 轮询
在这里,我们需要引入除了Map和Reduce以外的另外两种Task,WaitingTask和StopTask,并修改worker主函数,使其成为可“复用”的worker,在一个循环中不断地进行拿任务—>做任务—>拿任务的循环。
// ====================== mr/worker.go ======================
const (
MapTask TaskType = 0
ReduceTask TaskType = 1
WaitingTask TaskType = 2
StopTask TaskType = 3
)
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
os.Mkdir("tmp", os.ModePerm)
task := WorkerTask{MapFunc: mapf, ReduceFunc: reducef}
for {
task.CallForAllocateTask()
switch task.Type {
case MapTask:
task.DoMap()
case ReduceTask:
task.DoReduce()
case WaitingTask:
time.Sleep(1 * time.Second)
case StopTask:
return
default:
panic("Invalid Task state received by worker")
}
}
}
3.4.1 Master 分配
因为引入了两种新的Task,所以Master在分配的时候也需要额外进行考虑,作出一下修改:
// ====================== mr/master.go ======================
func (m *Master) AllocateTaskHandle(arg *NoArgs, reply *AllocateTaskReply) error {
if m.ReduceDone {
reply.Type = StopTask
return nil
}
select {
case mapIdx := <-mapAllocateId:
reply.FileName = m.FileNames[mapIdx]
reply.MapId = mapIdx
reply.Type = MapTask
reply.ReduceNum = m.ReduceNum
reply.MapNum = m.MapNum
reply.WorkerId = int(atomic.AddInt32(&m.WorkerId, 1))
m.MapWorker[mapIdx] = reply.WorkerId
go m.timerForWorker(MapTask, mapIdx)
return nil
case reduceIdx := <-reduceAllocateId:
reply.ReduceId = reduceIdx
reply.Type = ReduceTask
reply.ReduceNum = m.ReduceNum
reply.MapNum = m.MapNum
reply.WorkerId = int(atomic.AddInt32(&m.WorkerId, 1))
m.ReduceWorker[reduceIdx] = reply.WorkerId
go m.timerForWorker(ReduceTask, reduceIdx)
return nil
default:
reply.Type = WaitingTask
return nil
}
}
最后需要给出Master退出的时间,根据实验手册,我们只需要在Done()方法中说明结束时机即可,也就是ReduceTask全部完成的时候。
main/mrmaster.goexpectsmr/master.goto implement aDone()method that returns true when the MapReduce job is completely finished; at that point,mrmaster.gowill exit.
// ====================== mr/master.go ======================
//
// main/mrmaster.go calls Done() periodically to find out
// if the entire job has finished.
//
func (m *Master) Done() bool {
ret := false
// Your code here.
ret = m.ReduceDone
return ret
}
至此,我们的MapReduce程序就可以跑起来了。你可以手动启动1个master和n个worker,完成wordcount。当然,也可以运行test-mr.sh进行检测,但是大概率会FAILED,因为我们目前实现的是理想化的版本,还没考虑worker节点宕机的情况。
3.5 错误容忍
3.5.1 定时器
在master分配任务的时候(AllocateTaskHandle),我们留了一个TODO,这里我们进行补充。
对于每一个Task,我们可以通过go route启动一个定时器来监控,如果超过一定的时间未完成,则将状态改为IDLE,重新进入到待分配的状态。
这里的时间我们根据实验手册假定为10s,超过10s即认为worker死亡
For this lab, have the master wait for ten seconds; after that the master should assume the worker has died (of course, it might not have).
// ====================== mr/master.go ======================
func (m *Master) AllocateTaskHandle(arg *NoArgs, reply *AllocateTaskReply) error {
if m.ReduceDone {
reply.Type = StopTask
return nil
}
select {
case mapIdx := <-mapAllocateId:
reply.FileName = m.FileNames[mapIdx]
reply.MapId = mapIdx
reply.Type = MapTask
reply.ReduceNum = m.ReduceNum
reply.MapNum = m.MapNum
reply.WorkerId = int(atomic.AddInt32(&m.WorkerId, 1))
m.MapWorker[mapIdx] = reply.WorkerId
go m.timerForWorker(MapTask, mapIdx)
return nil
case reduceIdx := <-reduceAllocateId:
reply.ReduceId = reduceIdx
reply.Type = ReduceTask
reply.ReduceNum = m.ReduceNum
reply.MapNum = m.MapNum
reply.WorkerId = int(atomic.AddInt32(&m.WorkerId, 1))
m.ReduceWorker[reduceIdx] = reply.WorkerId
go m.timerForWorker(ReduceTask, reduceIdx)
return nil
default:
reply.Type = WaitingTask
return nil
}
}
func (m *Master) timerForWorker(taskType TaskType, idx int) {
ticker := time.NewTicker(10 * time.Second) // 10 second failed, according to the guide book
defer ticker.Stop()
for {
select {
case <-ticker.C:
if taskType == MapTask {
m.MapStatus[idx] = IDLE
return
} else if taskType == ReduceTask {
m.ReduceStatus[idx] = IDLE
return
}
default:
if taskType == MapTask {
if m.MapStatus[idx] == Completed {
return
}
} else if taskType == ReduceTask {
if m.ReduceStatus[idx] == Completed {
return
}
}
}
}
}
3.5.2 WorkerId
我们为每个worker分配一个WorkerId,主要是用于错误恢复的情况。
我们考虑两种超时失效的情况
- worker挂掉,超时,worker直接死掉
- worker出现一些问题,超时,过后worker恢复
对于第一种情况,master在定时器超时后将task重新标记为IDLE,会重新将task分配给后续请求的worker执行。
对于第二种情况,master在先将task分配给worker A,A出现问题,定时器超时后将task重新标记为IDLE,重新将task分配给后续请求的worker B执行。此时如果A恢复正常,发回的report也会因为workerId不一致(A!=B)而不被master受理,避免影响。
事实上,该实验的test只考虑了第一种情况。
3.5.2 临时文件
- To ensure that nobody observes partially written files in the presence of crashes, the MapReduce paper mentions the trick of using a temporary file and atomically renaming it once it is completely written. You can use
ioutil.TempFileto create a temporary file andos.Renameto atomically rename it.
同样是考虑先前超时失效的第二种情况,为了防止在异常情况下多个 worker 执行同一个任务时输出到同样的文件里面,一个小技巧是先输出到 temp 文件里,完成后再原子地重命名为最终文件。这个在 MapReduce 的论文和 lab1 的实验手册里面都有提到。
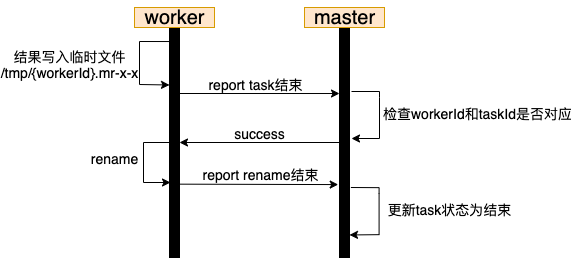
一个比较好的流程应该如下图所示,在任务完成阶段进行两次握手
注:这里的第二次握手(report rename)目的是通知master文件已生成。以map task为例,如果没有这次握手,可能master会在rename成功前将reduce task分配给某个worker,此时执行reduce task的worker读不到正确的rename后文件,会出错。
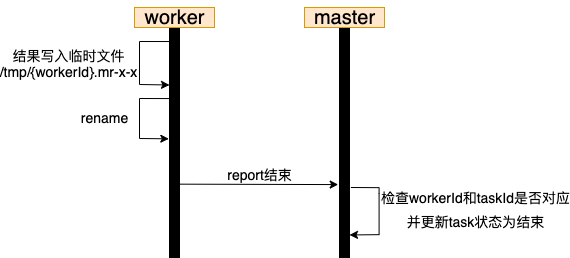
但是在本次实验中,由于是share disk的结构,我们只需保证task在未结束前不产生“半成品”的文件即可,换言之,task任务结束可以直接将临时文件rename、再通知master,简化后的流程如下:
实现时需要在worker初始化时候确保temp目录的创建
// ====================== mr/worker.go ======================
var tmpDir string = "tmp/"
//
// main/mrworker.go calls this function.
//
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
os.Mkdir("tmp", os.ModePerm)
task := WorkerTask{MapFunc: mapf, ReduceFunc: reducef}
for {
task.CallForAllocateTask()
switch task.Type {
case MapTask:
task.DoMap()
case ReduceTask:
task.DoReduce()
case WaitingTask:
time.Sleep(1 * time.Second)
case StopTask:
return
default:
panic("Invalid Task state received by worker")
}
}
}
修改doMap和doReduce方法,先写入临时文件,后统一进行rename
// ====================== mr/worker.go ======================
func (task *WorkerTask) DoMap() {
data, err := ioutil.ReadFile(task.FileName)
if err != nil {
fmt.Printf("file read err %s \n", task.FileName)
return
}
kvs := task.MapFunc(task.FileName, string(data))
intermediate := make([][]KeyValue, task.ReduceNum)
for _, kv := range kvs {
idx := ihash(kv.Key) % task.ReduceNum
intermediate[idx] = append(intermediate[idx], kv)
}
// write to temp intermediate files
prefix := fmt.Sprintf("map%d", task.WorkerId)
for i := 0; i < task.ReduceNum; i++ {
intermediateFileName := fmt.Sprintf("%s.mr-%d-%d.*",prefix,task.MapId, i)
file, fileErr := ioutil.TempFile(tmpDir,intermediateFileName)
if fileErr != nil {
fmt.Printf("file create error %s,%s \n", intermediateFileName,fileErr)
return
}
defer file.Close()
enc := json.NewEncoder(file)
for _, kv := range intermediate[i] {
encodeErr := enc.Encode(kv)
if encodeErr != nil {
fmt.Printf("encode error %s \n", intermediate[i])
return
}
}
}
task.RenameTempFile(prefix)
success := task.ReportWorkerTask(nil)
if success{
// 简化后,nothing to do
}
}
func (task *WorkerTask) DoReduce() {
kvsMap := make(map[string][]string)
// read local disk to load intermediate file
for i := 0; i < task.MapNum; i++ {
fileName := fmt.Sprintf("mr-%d-%d", i, task.ReduceId)
file, err := os.Open(fileName)
if err != nil {
fmt.Printf("file read err %s \n", fileName)
return
}
dec := json.NewDecoder(file)
for {
var kv KeyValue
if err = dec.Decode(&kv); err != nil {
break
}
_, ok := kvsMap[kv.Key]
if !ok {
kvsMap[kv.Key] = make([]string, 0)
}
kvsMap[kv.Key] = append(kvsMap[kv.Key], kv.Value)
}
}
// reduce to tmp file
prefix := fmt.Sprintf("reduce%d", task.WorkerId)
outFileName := fmt.Sprintf("%s.mr-out-%d.*", prefix,task.ReduceId)
outFile, _ :=ioutil.TempFile(tmpDir,outFileName)
defer outFile.Close()
for key, val := range kvsMap {
reduceRes := task.ReduceFunc(key, val)
fmt.Fprintf(outFile, "%v %v\n", key, reduceRes)
}
task.RenameTempFile(prefix)
success := task.ReportWorkerTask(nil)
if success{
// 简化后,nothing to do
}
}
func (task *WorkerTask) RenameTempFile(prefix string) {
// rename file
files, err := ioutil.ReadDir(tmpDir)
if err != nil {
fmt.Println("read temp dir error")
}
for _,info := range files{
if strings.HasPrefix(info.Name(),prefix){
intermediateFileName := strings.Split(info.Name(),".")[1]
os.Rename(tmpDir+info.Name(),intermediateFileName)
}
}
}
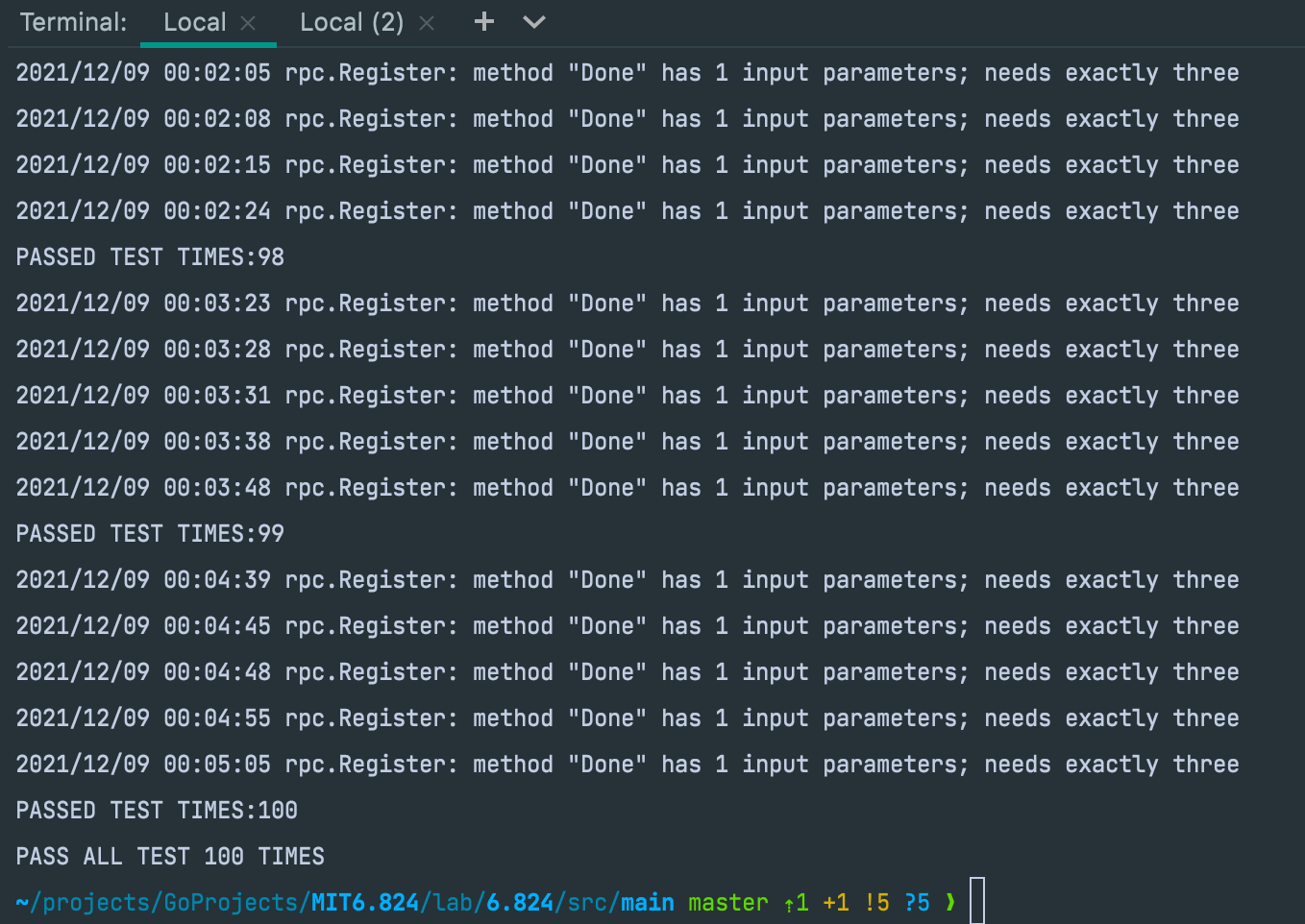
4 结果验证
一次通过test-mr.sh并不能保证正确性,因此我在main目录下新建test-mr-loop.sh脚本,循环运行test-mr.sh进行测试
#!/bin/sh
str2="PASSED"
read -p "Enter loop times>" loop_time
i=0
success=true
pass="PASSED ALL TESTS"
while [ $i -lt $loop_time ]
do
let 'i++'
sh test-mr.sh > test.log
result=$(tail -n 1 test.log|awk '{print substr($0,length($0)-16)}')
if [[ $result =~ $str2 ]];then
echo "PASSED TEST TIMES:"$i
else
success=false
echo "FAIL AT" $i "TIMES"
break
fi
done
if ($success)
then
echo "PASS ALL TEST" $loop_time "TIMES"
fi